iToF|用于低功耗和自优化带片上ISP的1.2Mp的iToF传感器
引言
我们提出了一种i-ToF来改善功耗和运动伪影。在实现应用程序时需要深度信息的AR/VR和机器人设备在使用i-ToF时由于有限的功率和移动运动特性而受到限制。特别地,出现了根据高分辨率的实现的AP操作量的增加以及由于多帧操作而导致的延迟时间的限制。所提出的传感器具有嵌入式深度处理器,用于处理传感器内部的深度计算,并通过使用28nm工艺实现低功耗实现。此外,通过以250FPS的读出速度操作,减少了运动伪影。结果显示,传感器本身可以实现输出30FPS的深度输出,并且功耗降低了90%。
1. Introduction
近年来,3D信息被用作机器视觉的基本信息,如AR/VR中的3D地图生成和手势控制以及具有RGB图像的机器人。由于其基于电池的操作,这些设备需要低功率操作,并且由于发生连续运动,因此需要减少运动和恒定的FPS。此外,主要考虑使用间接ToF(i-ToF)的高分辨率深度信息,因为由于使用表面信息的应用程序的特性,需要高分辨率的深度信息。在先前的研究中,提出了通过解调对比度(DC)的提高、调制频率的提高和抽头失配校准来提高深度性能和距离。然而,由于所有深度处理都是在应用处理器(AP)中基于软件的,因此降低总体系统功率是有限制的。此外,根据AP的性能,FPS和深度质量是不同的。
此外,由于多个传感器同时用于跟踪和检测,因此传输到AP的数据量和计算负担进一步增加。作为另一个问题,由于外部光条件在曝光时间期间累积,因此与室内相比,室外环境中的操作距离减小,并且噪声增加。为了解决这个问题,提出了一种通过外部控制转换模拟装仓和数字装仓的方法,分别实现信号增加和FWC增加效果。然而,存在这样的问题,即增加了用于确定外部光状况的传感器,或者需要通过AP中的附加计算来改变操作模式。在本文中,提出了以下三个改进方案,即在传感器中内置嵌入式深度处理器单元(eDPU):
- 1)降低系统功率;
- 2)最小化运动伪影
- 3)减少外部条件的影响
2.基本操作
i-ToF是通过反射回物体的调制发射机信号的相位延迟来计算距离。为此,需要每个周期分为四个的相位信息,并且通过将其分为一个像素内的每个抽头来感测相位信息。此功能将减少噪声并提高精度。然而,由于制造过程中的失配,每个抽头都具有增益和偏移误差。为了补偿这一点,通常使用连续的2帧信息,因为在附加帧中应用抽头混洗。此外,由于调制的周期性,最大操作距离受到作为折叠误差的频率(fm)的限制。为了解决这个问题,通过对两个或多个fm进行交叉运算,通过最大公约数(GCD)运算来确定实际距离。结果,当计算基于i-ToF的处理时,使用2到4个基于多帧的计算。结果,延迟增加,所需的计算量增加。
3.芯片架构
下图显示了所提出的具有深度处理器的传感器的框图:
![]()
单位像素由2x2个子像素组成,每个子像素由4抽头(A、B、C、D)组成。在光栅极驱动器信号的控制下,在曝光积分时间(EIT)部分期间存储相位信息。在EIT之后,使用相关双采样(CDS)和计数器对模拟信号进行数字化。这些数据通过预处理块进行相位重新排序,并存储在由多达4页的原始数据组成的帧存储器中,用于混洗和多频率。该信号通过内置在传感器中的深度处理单元被转换成深度信息。eDPU执行相位延迟计算、非理想和透镜校准、空间滤波和时间滤波,以计算深度和增强。通常,硬连线逻辑的缺点是只能进行预定义的操作。然而,所提出的eDPU用硬连线逻辑实现简单的数学运算(例如,相位延迟感测),并且需要根据应用程序更改功能的部分(如滤波)是可编程配置的。环境光检测器(ALD)使用从eDPU计算的强度和幅度来计算环境光环境,并通过传感器本身确定装仓模式。此信息传递到预处理块以进行日期重新排序。如图1底部所示,在模拟装仓的情况下,由于2x2个子像素的求和信号被一次读取以增加信号。在数字装仓的情况下,从所有像素捕获1280x960个信号以增加全阱容量(FWC),并通过预处理块中的平均值转换为640x480。
芯片时序图如下图所示,所提出的eDPU支持各种系统场景,并通过基于混洗、多频率和基于深度帧的ISP计算优化原始帧速率来最小化运动伪影。
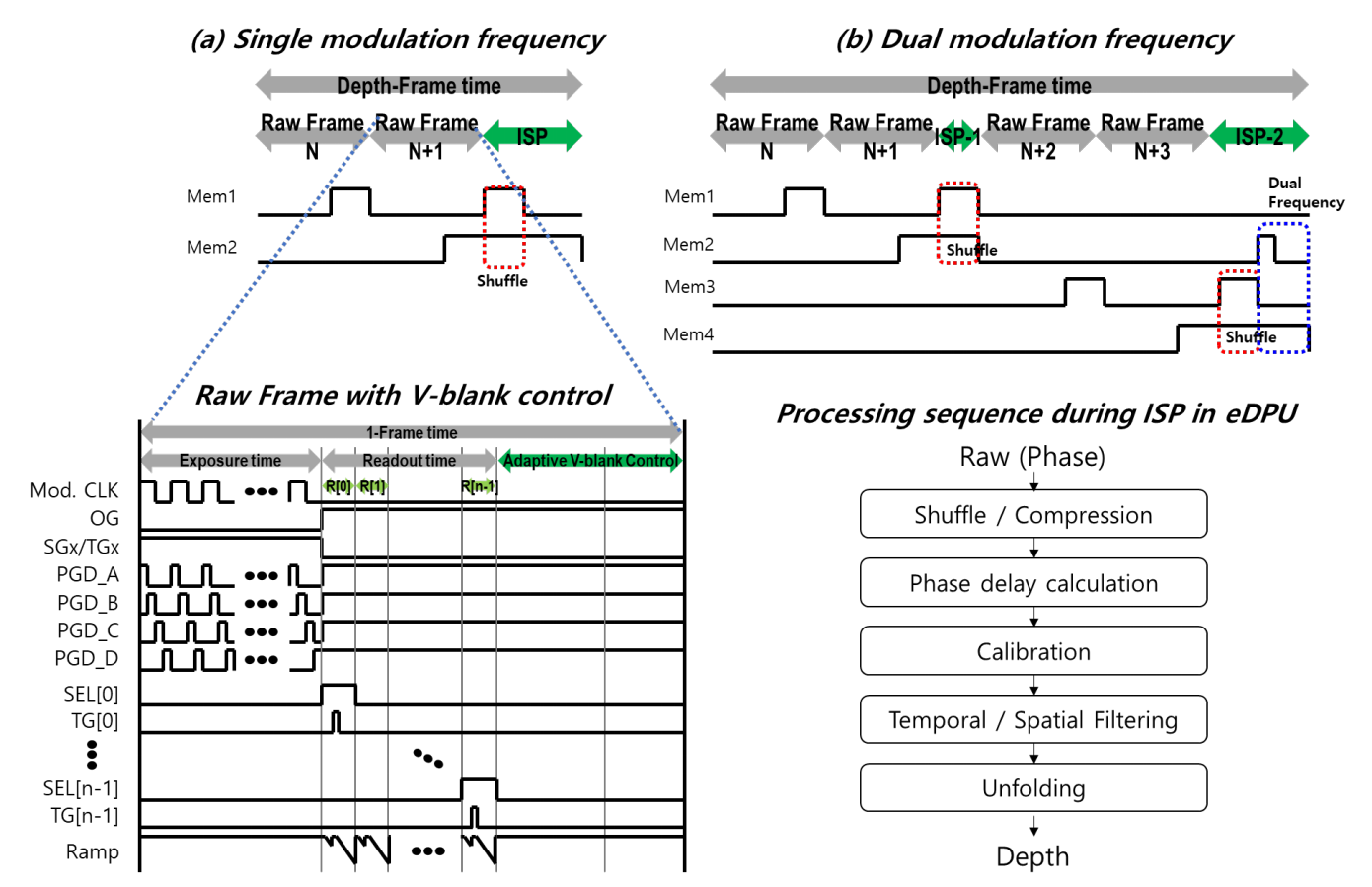
另外上图中(a)显示了在单频调制(s-fm)下的混洗操作。它使用两个帧来计算深度,并且具有最小化运动的强度。然而,由于操作距离仅由调制频率决定,因此适用于短距离操作。对于内存大小优化,非混洗数据(n帧)直接存储在帧内存中,混洗帧数据(n+1帧)使用行内存计算混洗,然后压缩数据存储在帧存储器中。接下来,通过相位延迟和滤波操作来输出深度信息。上图(b)显示了双频调制(d-fm)的工作情况。尽管运动滞后时间由于基于四帧信息而增加,但它在通过增加距离和高频调制来确保高性能深度方面具有优势。对与调制第一频率(f1)相对应的数据(n,n+1帧)进行混洗,然后将计算出的相位延迟存储在存储器中,并且在读出第二频率(f2)的(n+2,n+3帧)数据之后,执行混洗、校准、滤波和展开操作。该序列可以根据应用分别支持运动减少和距离增加。
4. 实现与结果
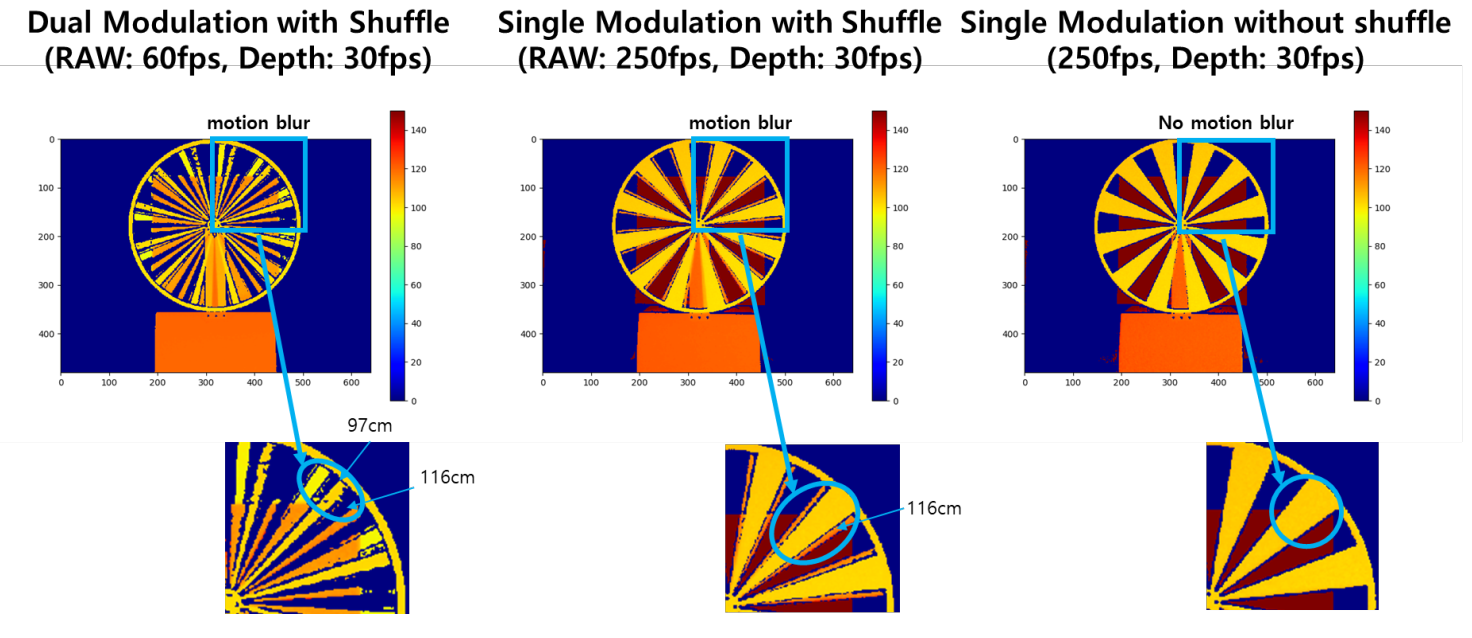
由于EDPU和帧存储器的实现,拟议的传感器采用2堆栈结构,顶部芯片采用65nm背面照明(BSI)的像素阵列,底部芯片采用28nm逻辑工艺制造,用于芯片尺寸优化。为了最小化运动,原始数据以250 fps运行,图3显示了以100 rpm旋转的实验结果,以检查运动工件的效果。运动滞后时间定义为从第一个原始帧开始到最后一个帧。在双频操作期间,出现25.39毫秒的滞后时间。下图(a)显示了60fps原始帧条件下双频(f1=100MHz,f2=30MHz)操作的实验结果。由于50.38ms滞后时间,移动区域的深度信息被扭曲,可以确认某些区域由于低SNR退化而被屏蔽。图(b)显示了在FM=50MHz时应用洗牌的情况,延迟时间为8.73ms。这表明错误区域减少了。此外,如图(c)所示,当排除洗牌时,可以确保运动自由性能,但由于点击不匹配,噪声特性会恶化两次。
下图显示了所提出的传感器的深度和eDPU性能。
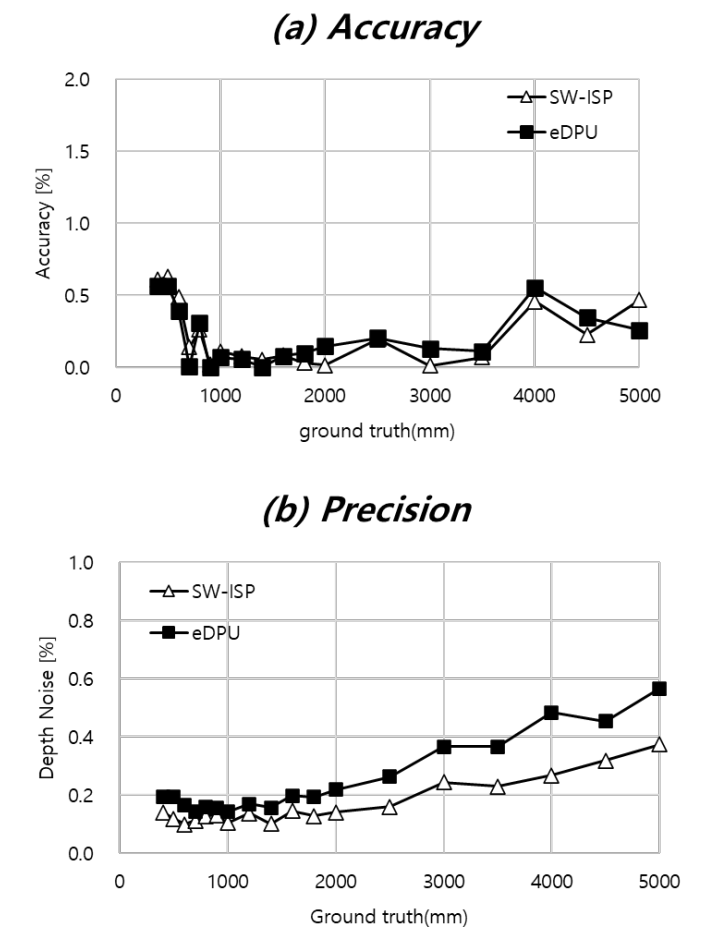
为了进行评估,透镜使用F/1.3,78°FoV,发射器使用940nm 3.4W峰值功率的垂直腔面发射激光器(VCSEL)。最大EIT被设置为0.4ms,并且通过在主控制器中控制曝光时间来防止饱和。为了与SW-ISP进行性能比较,实验使用AP处理器(HDK8350,64位浮点)通过实现640x480分辨率的相同功能。比较结果表明,在工作范围(0.4-5m)内,精度小于0.6%。深度噪声小于0.57%,但与SW-ISP相比降低了0.2%。原因是在用于优化帧存储器容量的压缩处理期间量化噪声增加。延迟时间比较为13.59ms,输出数据量也减少到6.25%~12.5%。处理功耗仅为0.12W,比SW-ISP减少了90%,如图下图所示:
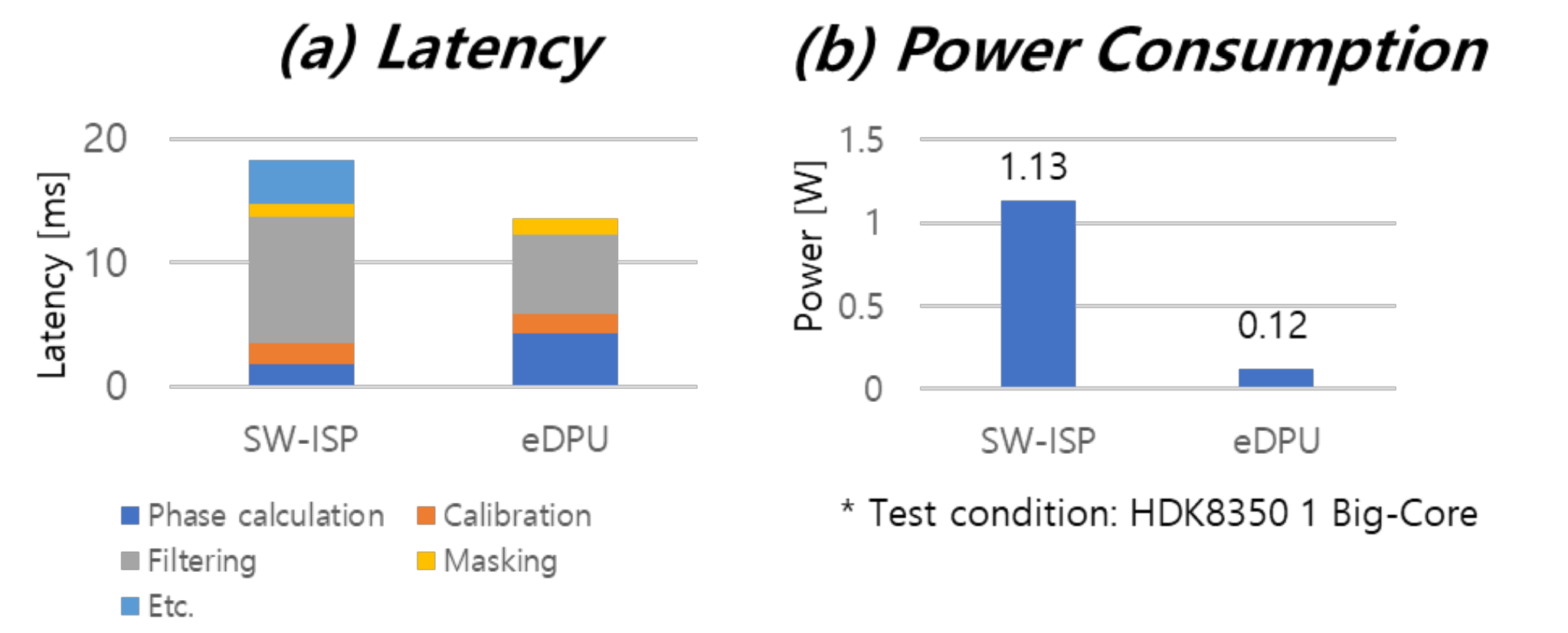
最后,传感器+深度操作功率从1.4W降低到0.29W。上图显示了根据环境条件的深度性能。
5. 结论
本文拟议的i-TOF系统支持小型化设备的低功耗设计,如带有嵌入式ISP的AR/VR。此外,与SW相比,性能和高速FPS相同。通过这种方式,在实施应用程序和系统时,可以更容易、更高效地使用深度数据。
6. 结束语
好了今天就到这里,希望今天可以给您带来对于传感器的更深的认知,喜欢的同学可以进行朋友圈分享以及点击文章在看。另外,对论文感兴趣的同学可以follow我的Github论文仓库,也可以加入知识星球以及交流群,获取一手行业资料~
加入星球:

如果您对ADAS感兴趣,欢迎关注我的公众号、知乎、Github、CSDN等,同时发表文章中使用源码以及文章会在我的GitHub进行开源,如果您有感兴趣话题也可以后台私信。